Abstract
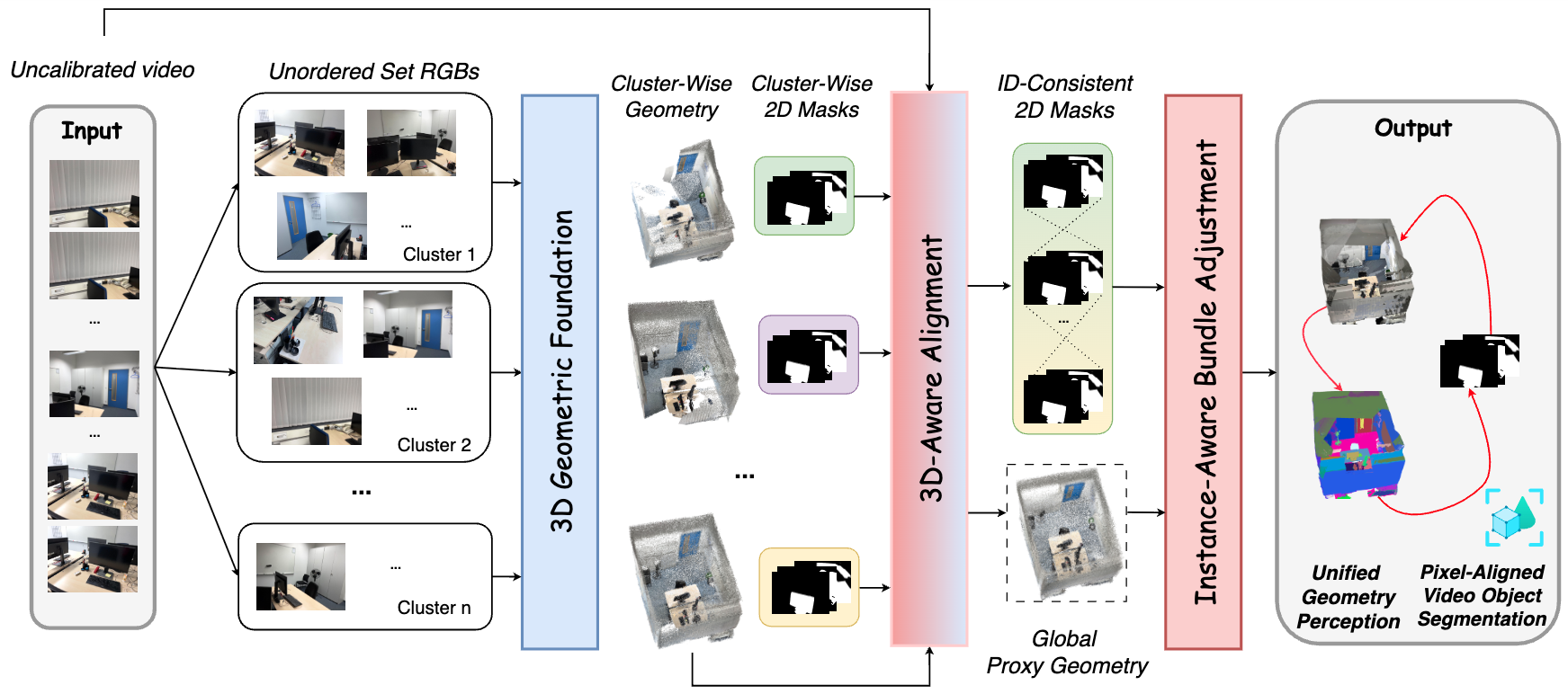
We present Scale3D, a unified framework for scalable 3D reconstruction and scene understanding from complex and long image sequences. Existing methods typically emphasize either geometric reconstruction or object-level understanding, but struggle to maintain both global geometric consistency and coherent instance identities over hundreds to thousands of views. Our key insight is to exploit their mutual synergy: geometry provides a robust basis for cross-view object association, while perception regularizes and refines geometry. Scale3D decomposes long video into overlapping clusters, reconstructs cluster-wise geometry and 2D segmentation masks, and introduces a 3D-Aware Alignment module to align local predictions into a global proxy geometry while recovering temporally coherent, globally ID-consistent video object segmentation. We further propose Instance-Aware Bundle Adjustment, leveraging dense instance-consistent correspondences to refine the camera poses and geometry. We evaluate Scale3D on ScanNet200 and ScanNet++v2 across three different benchmarking tasks: 3D reconstruction, class-agnostic 3D instance segmentation, and panoptic lifting for novel-view rendering. It achieves state-of-the-art results, improving AUC@30 by 5%, AP by 11%, and Panoptic Quality by 10%. Overall, our results highlight the importance of jointly modeling geometry and perception for scalable scene reconstruction and understanding over long image sequences with hundreds to thousands of views.